Data Workshop
Data Workshop
Data Workshop is a platform designed for building complex projects that implement machine learning, artificial intelligence, custom APIs, ETL, or custom data pipelines. It serves as a workspace for creating specialized solutions to address specific problems within any data-driven organization.
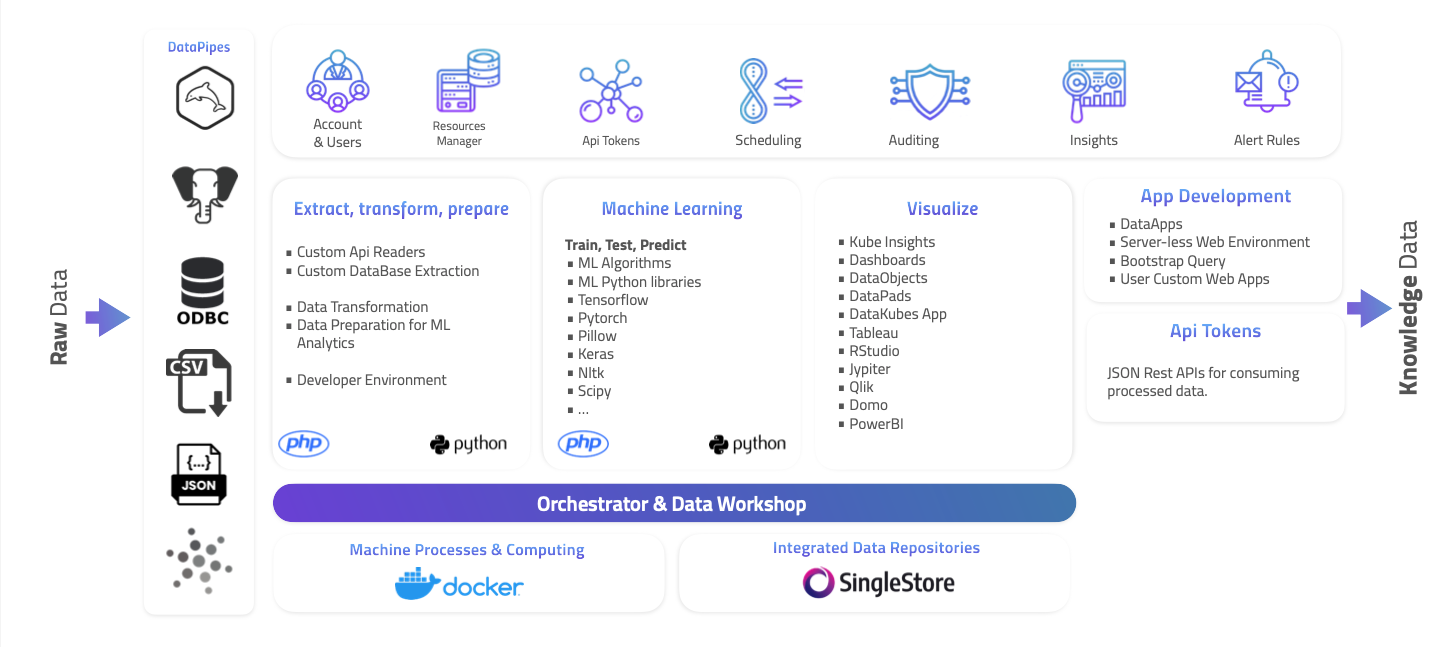
Being a comprehensive data management platform within an organization, DataKubes offers limitless possibilities for creating solutions. With complete development, visualization, storage, processing, integration, and more tools, your data team can implement a wide range of solutions within DataKubes.
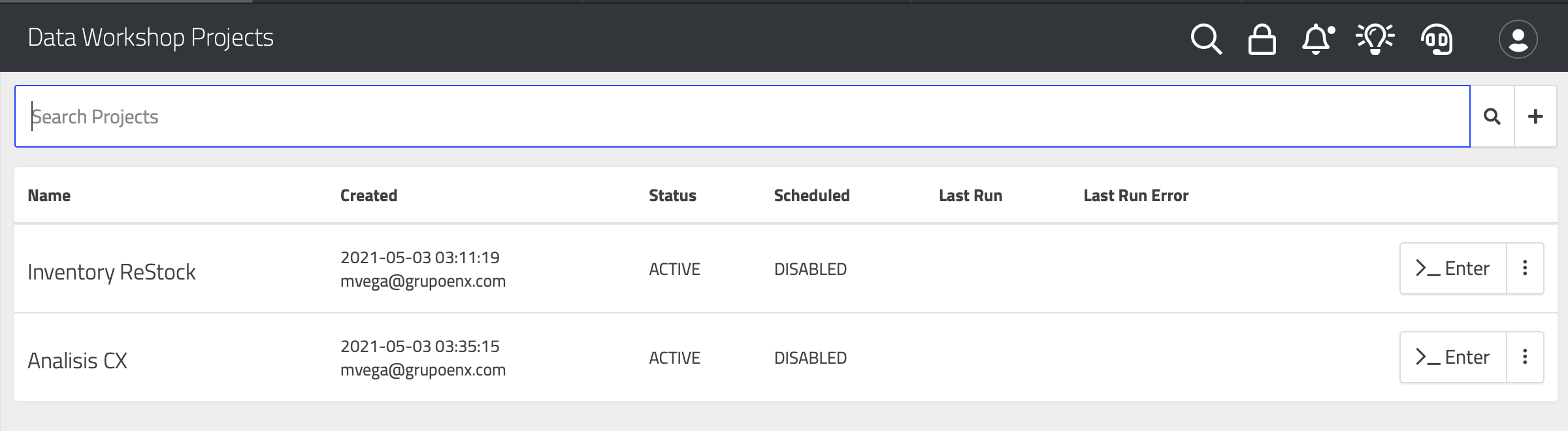
Projects
Projects are workspaces within the DataKubes Data Workshop (DK-DW), where different types of objects are grouped according to the following classification within a data solution flow.
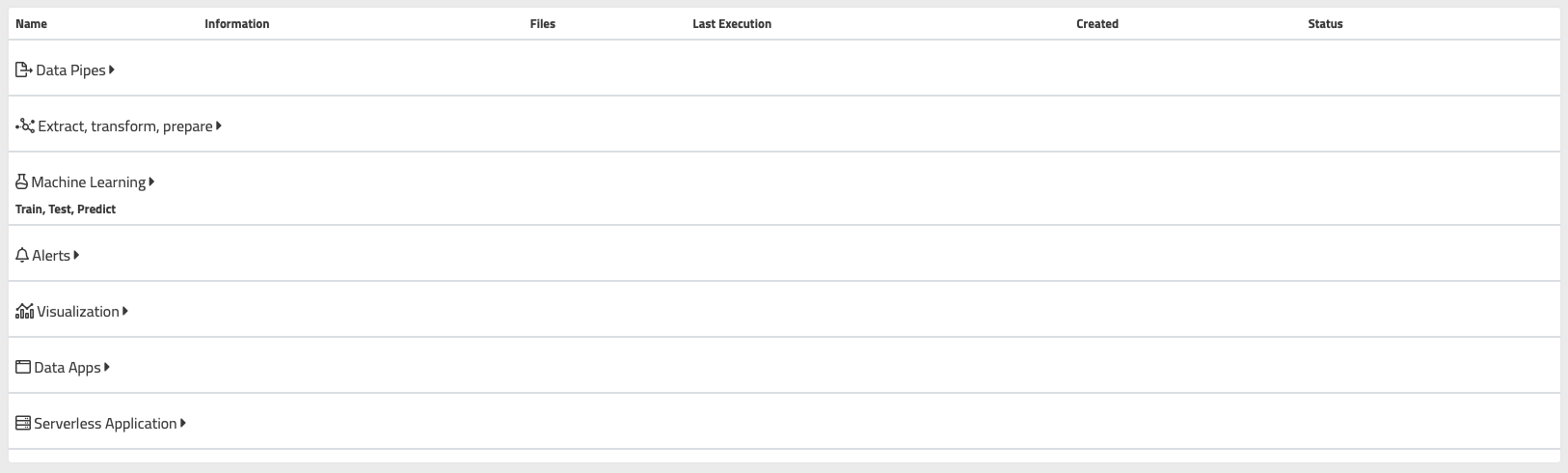
-
Data Pipes: Use DataKubes DataPipes to input data into your model. You can extract data from MySQL, PostgreSQL, CSV, JSON, and ODBC into your repository's tables.
-
Extract, transform, prepare: These objects allow you to extract data from complex or unsupported sources, transform and prepare existing data in the repository.
-
Machine Learning (Train, Test, Predict): Create objects that enable you to train, test, and build models that predict future results using algorithms and Machine Learning libraries, using the tables in the project's repository.
-
Alerts Rules: These objects consist of development objects for complex data rule analysis to find matches and notify, as well as Alert Rules that are part of the project.
-
Visualization: Objects that utilize DataKubes analytics engine to visualize the results of data models and processes applied to data in the repositories.
-
Data Apps: Create applications that easily consume processed data in Data Workshop. DataApps is DataKubes' visual engine for building data-consuming apps.
-
Serverless Application: Create applications that run in persistent containers for collecting, managing, or even delivering complete applications to end-users within your organization.
Creating a Project
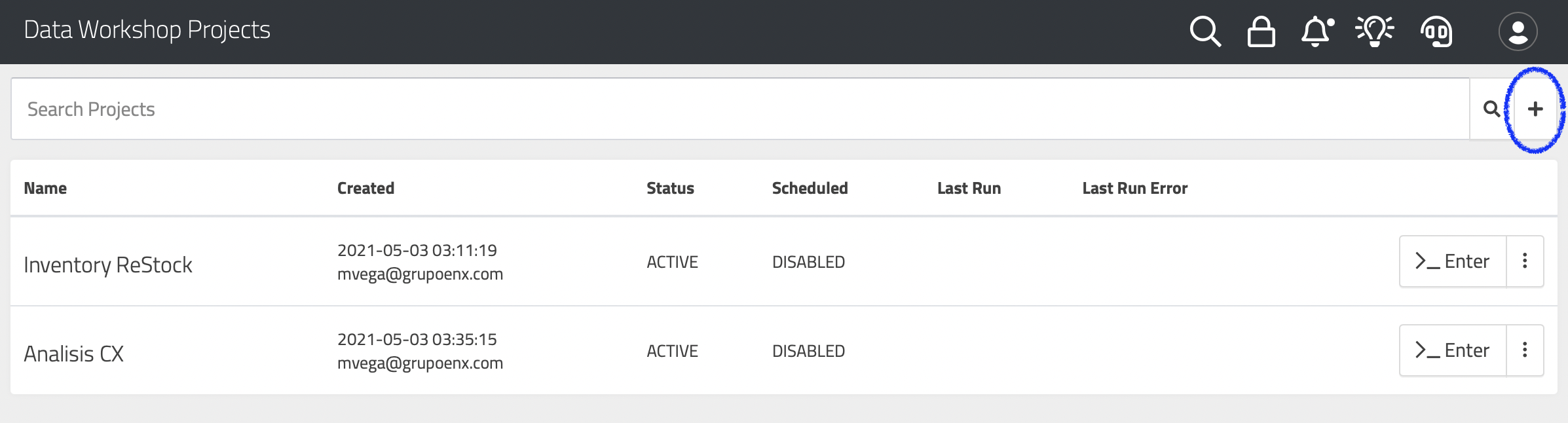
To create a project in Data Workshop, simply use the "+" icon next to the search bar, as shown in the following image:
This will open the project creation screen, which will prompt you for the necessary details to identify it.
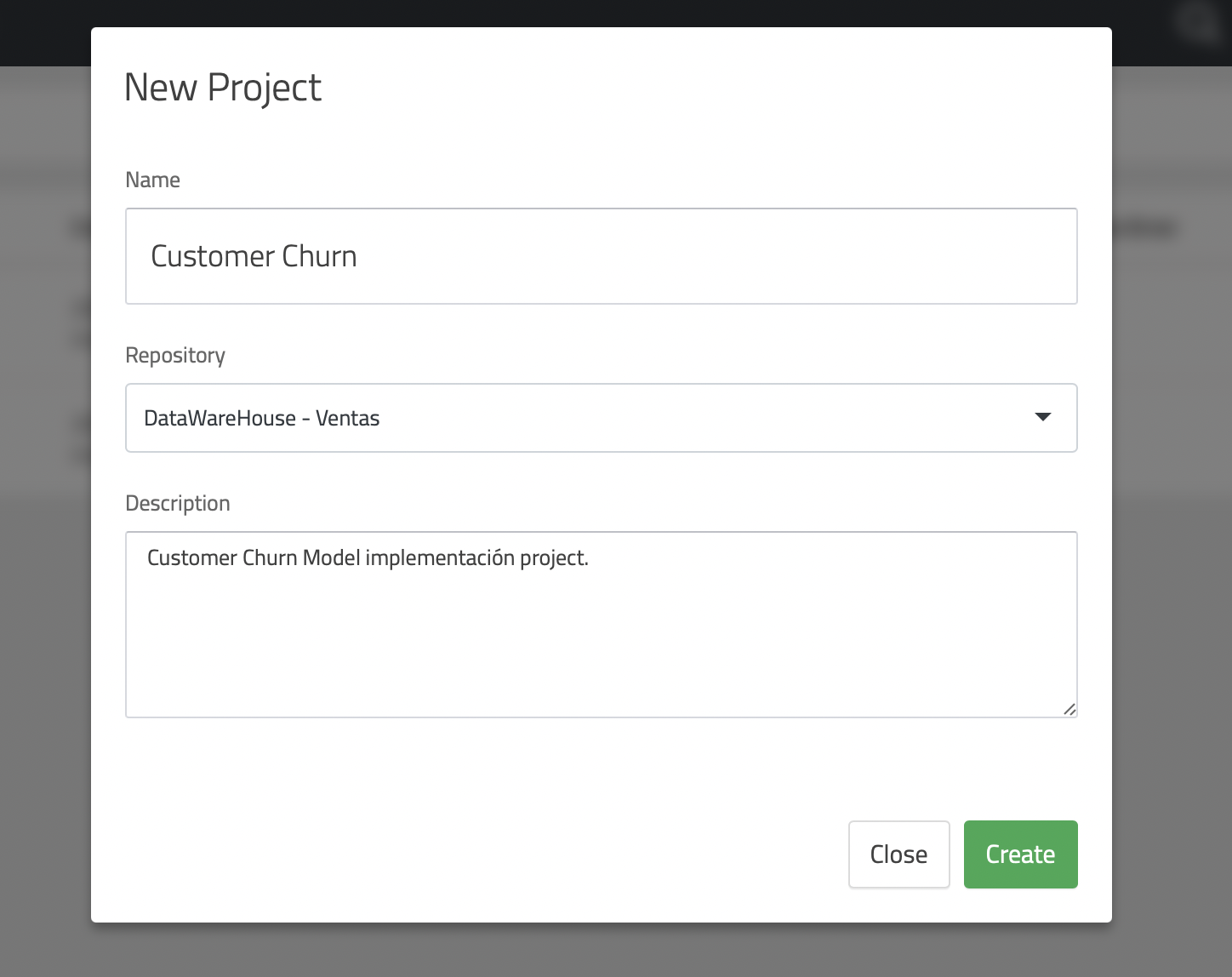
Once the project has been created, you can create the different objects you need.
Development Environments in Data Workshop
Currently, DataKubes Data Workshop supports development environments based on specific needs or specialties. These are:
PHP
This environment allows you to develop fast applications or processes that can be used for APIs, web applications, ETL, and more. The currently installed modules are:
Core, curl, date, ftp, gd, hash, iconv, imagick, imap, json, libxml, mbstring, mcrypt, mysqli, openssl, PDO, pdo_sqlite, redis, SimpleXML, sqlite3, zip, zlib, xml, xmlreader, xmlwriter.
Python
This environment is preferred for creating Machine Learning models and advanced analytics with its robust library of models and algorithms for making predictions and AI in your data objects. The currently preloaded modules include:
matplotlib, med2image, nibabel, pillow, pydicom, tensorflow, tensorflow-gpu, keras, mysqlclient, pyodbc, torch, torchvision, numpy, pandas, scipy, nltk, orjson.
WAC Web Application Container
This environment allows you to develop web applications or consumption APIs that persist as servers. The currently installed modules are:
Core, curl, date, ftp, gd, hash, iconv, imagick, imap, json, libxml, mbstring, mcrypt, mysqli, openssl, PDO, pdo_sqlite, redis, SimpleXML, sqlite3, zip, zlib, xml, xmlreader, xmlwriter, apache, mod_ssl, letsencrypt.
You can select the environment when creating objects in the project, as shown in the following image:
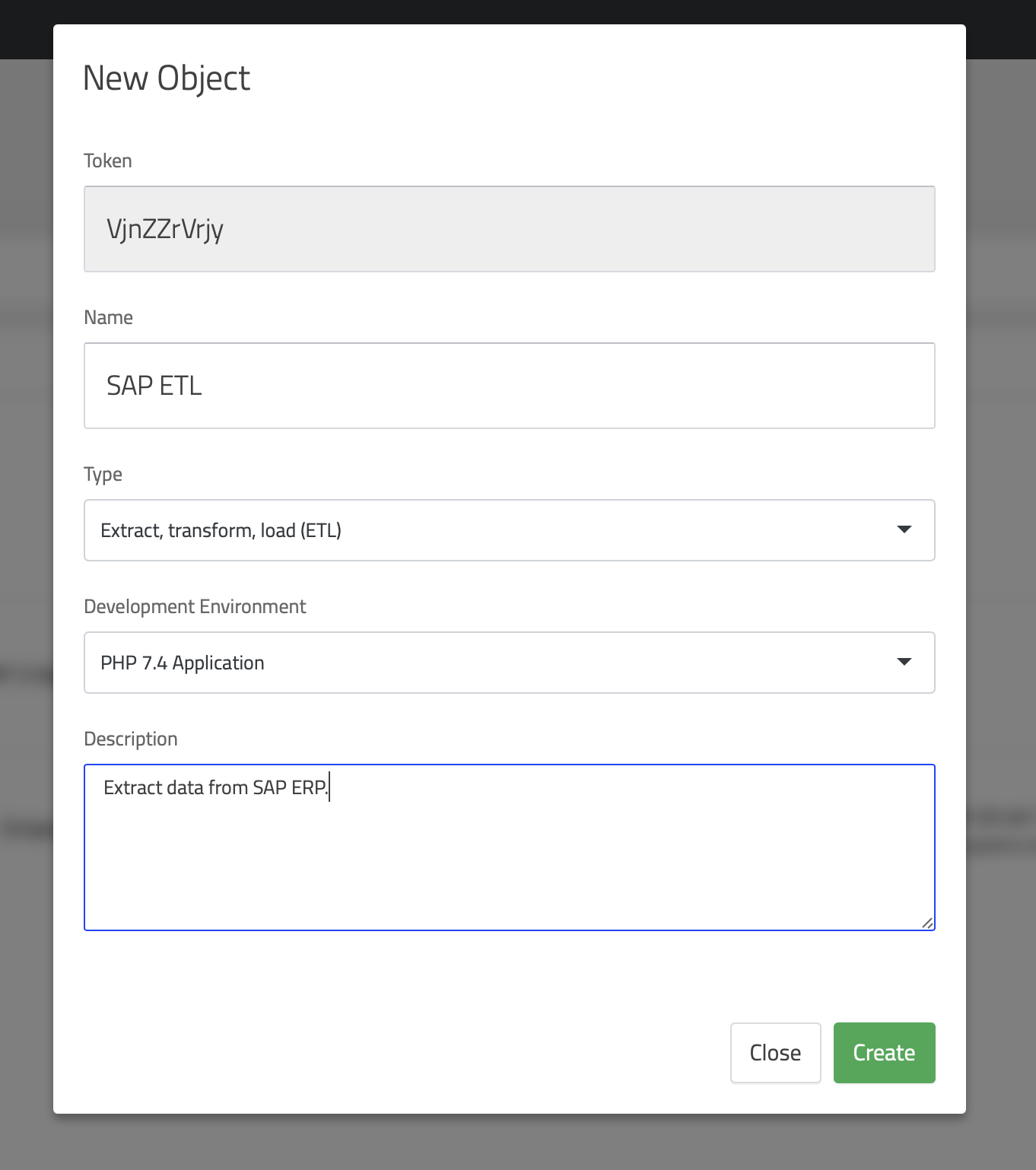
What Are Objects in a DK-DW Project
To create a complete AI solution, it requires many elements and processes. To better organize each project, it allows you to create objects that, in turn, contain complex processes that, when grouped, result in a solution to a specific need.
There are two categories of objects:
- Processing Objects
- Visualization Objects
Processing Objects
Processing objects are those that allow you to execute advanced code that reads, processes, applies ML models, and stores the results in the project's data repository.
Visualization Objects
Visualization objects are Kubes or DataKubes cubes used to easily visualize data using DataKubes' embedded visualization engine. Each Kube created in a project is available to users with permissions from Insights.
DataApps
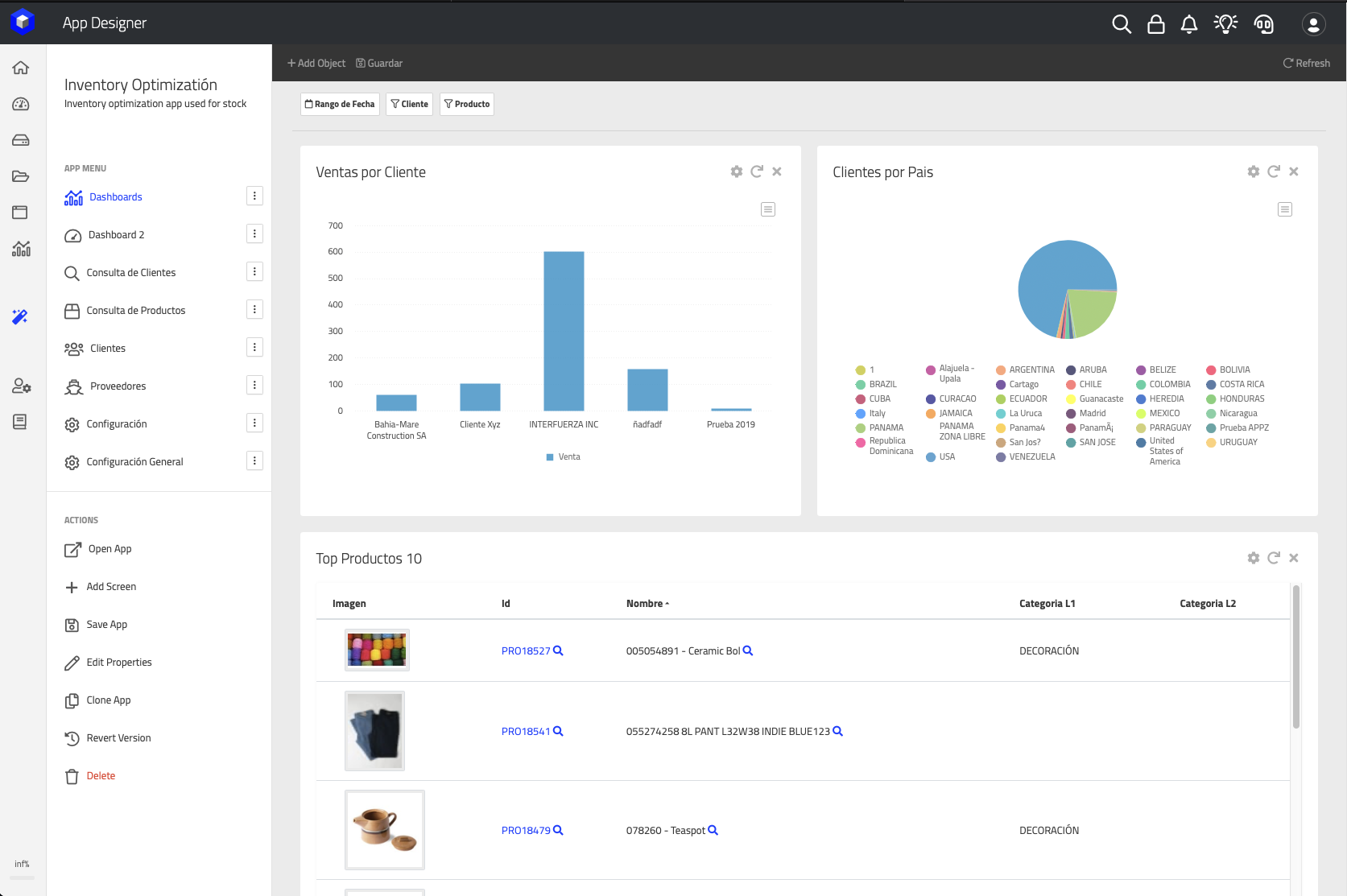
DataKubes includes a built-in application design engine that shares visual components and simplifies the work required to create user-friendly screens for users within your organization who need to consume data managed by DataKubes. DataApps has its own documentation section, which you can access at DataApps.
Serverless Objects (Containers)
These objects allow you to create applications that run continuously, serving custom applications to users or creating integration APIs waiting to be consumed at any time. These objects are allowed to be continuously active, unlike Processing Objects, which only run and return execution results every time they are activated, without remaining active.
Computing Resources in Data Workshop
DataKubes uses Dockers to run processing objects and daemon or application objects. They can be executed independently and securely. Currently, DataKubes uses two resource environments to run these containers:
-
DataKubes Shared Container Resources: This resource environment is shared with all users who require it. It is the most cost-effective and controlled way to implement complete data solutions, and you only pay for usage within this cluster.
-
DataKubes Dedicated Container Resources: This environment is a dedicated cluster with its own allocated computing resources for an organization. It has unlimited resource consumption and growth. This model is not charged per usage but for the dedicated resources assigned.
Every DataKubes account has access to the DK Shared Container Cluster, and it is charged based on usage as it is used.
Access to DK Dedicated Container ResourcesTo access this type of resources, it is necessary to upgrade to the Enterprise plan, which allows you to enjoy dedicated features.
Development Interface in Data Workshop
In addition to visualization objects, all other objects offer a development interface for creating applications quickly and easily.
If we enter a processing object such as Machine Learning, we can see the following image:

Each object allows you to add more files that will be compiled at the time of execution.
In the case of visualization objects, they are Kubes designed with the DataKubes visualization tool, as seen in our demo project:

Global Files
It is possible to create global files that are shared among objects of the same type throughout the project. These are useful for creating libraries and functions that will be shared across all objects in the same language.
To create a global file, it is created from any object in the project by clicking on "Create File":

When you create global files, they can be seen in the list on the left, as shown in the image:

Connecting to the Project's Data Repository
Every project, when created, defines the working repository. The repository contains the data tables that will be used in the project's objects. This repository is defined at the time of project creation in DK-DW, as shown in the following image:

Once the project is created, the repository cannot be changed. We recommend cloning the project.
Once the repository has been defined in the project, all objects will point to this repository to retrieve their data.
Development Objects
In the development objects in your developer environment, there are instructions on how to consume the repository defined in the project that is part of the object. For example, in our Python or PHP object, you can find a file called *welcome.py / welcome.php, which can be seen in the following image:

The content of this welcome file provides information on how to connect to the project's repository, depending on the selected platform.
Running Projects and Their Objects
Each object in a project, depending on whether it is supported by its type, can be run individually. For example, in the case of Processing Objects, we can see the following image:

Where the Run button allows you to view the execution flow of the object.

For serverless or daemon-type objects, they show additional options such as restart, turn on, and turn off to control the services provided by these objects. For example, in the following image:

In addition to control options, the system allows you to display the current status of the serverless container.
Cloning Projects and Objects
In the Data Workshop, we allow you to clone projects or objects within a project to streamline code or object reuse. This simplifies the work done and allows you to execute that work in another repository. When you clone an object, it will be cloned within the project to which the original object belongs. In the case of cloning projects, it allows you to clone a project and define a different repository.
Cloning a project to another repositoryWhen you clone a project to another data repository, it is important to recreate the tables used by the project, as they will not be cloned to the destination repository during cloning.
Scheduling Automatic Project Execution
Once your project is ready, you can schedule its automatic execution by clicking on "Schedule Execution" in the project list:

This will open the scheduling screen, which allows you to adjust the execution status, which can be:
Enabled - Enabled
Paused - Paused
Disabled - Disabled
You can also configure the settings for the months, days, and days of the week when you want the project to run.
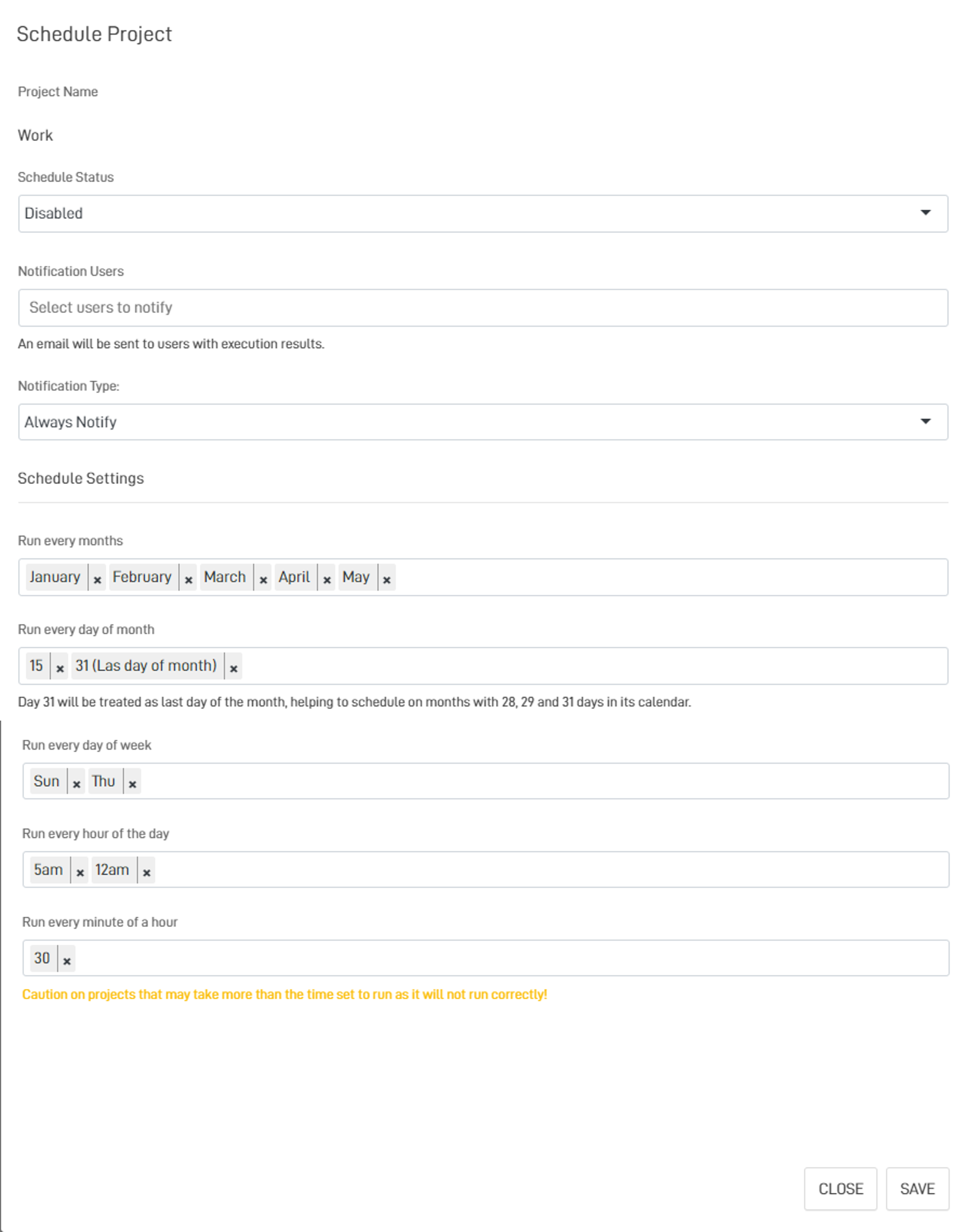
Project Execution HoursThe execution of projects depends on the configuration set by the user, designed this way for dynamic load management.
Updated over 1 year ago